GCP Architect's Corner ☁️ : Les dernières nouveautés Data - IA (et plus encore) sur Google Cloud Platform
AI values Data. Data values Business.
Unlocking Business Value through Data, Cloud, and Machine Learning Solutions
👋 Hello ! Je suis Vincent, Architecte IA et Lead Data Scientist. Avec ma société TerraQuant, j’aide les entreprises à exploiter leurs données et à intégrer des solutions d’intelligence artificielle pour générer de la valeur. Je me suis spécialisé dans la conception de solutions IA, et je conçois des architectures data performantes et évolutives. Besoin de conseils pour vos projets data ou IA ? 🚀 Je suis là pour vous aider à transformer vos idées en solutions concrètes ! Restez au courant de mes dernières actualités via mes newsletters.
SHARE
Semaine du 21 février au 27 février 2026
Bref résumé des news 📰 de la semaine
Une semaine riche en annonces du côté de l'IA avec de belles avancées sur les modèles génératifs et leurs intégrations en entreprise. Côté Data, nos bases de données managées font le plein de nouvelles fonctionnalités d'optimisation assistées par l'IA, tandis que les briques réseau et sécurité continuent de s'enrichir discrètement mais sûrement pour consolider nos architectures.
Le coin de l'architecte 📐
Avec l'usage de plus en plus croissant de LLMs directement dans nos applications, les bonnes pratiques de développement doivent s'adapter pour vérifier que ce qui part en production, devenu maintenant par nature "non-déterministe", puisse être évalué et monitoré pour garantir l'effet attendu.
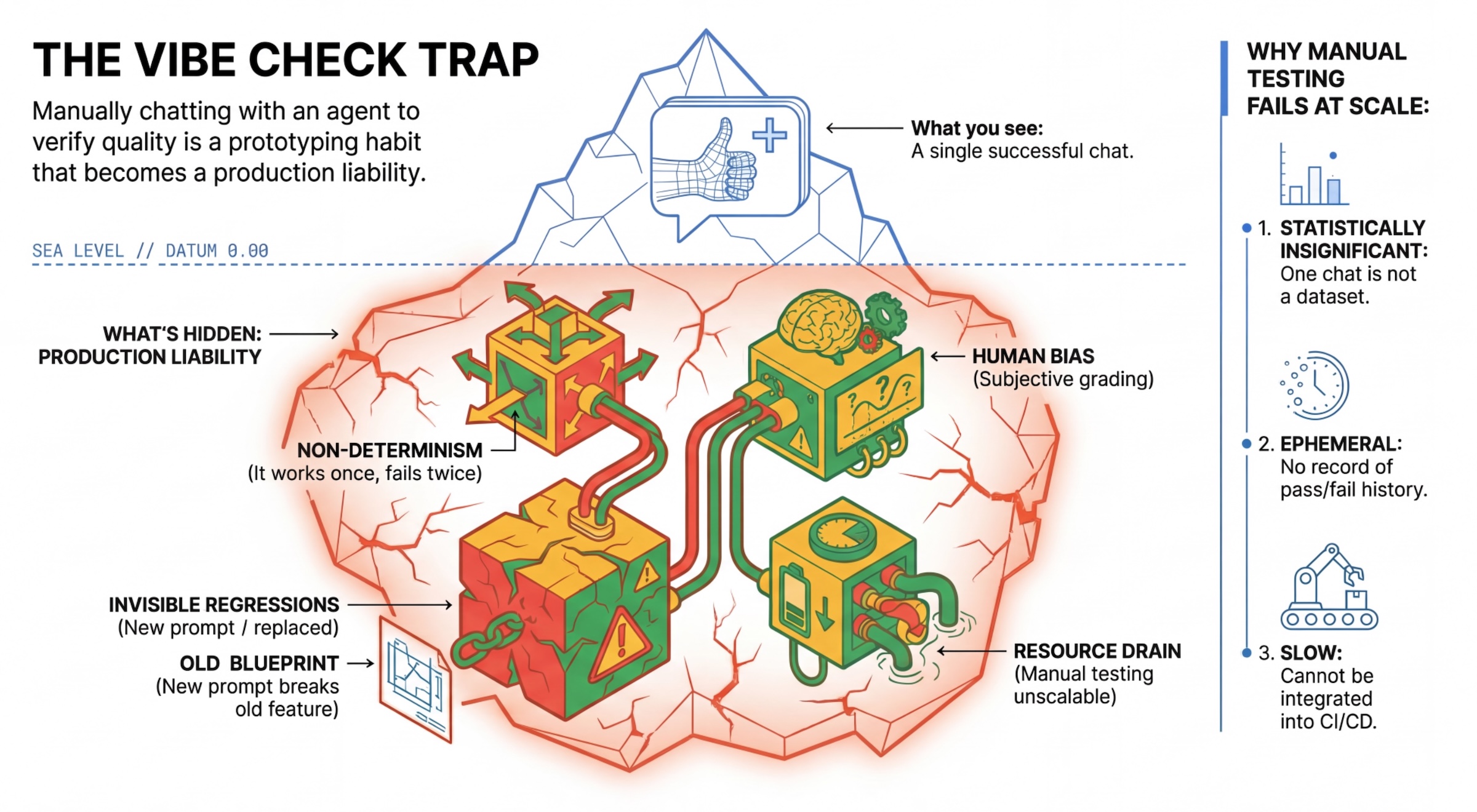
C'est exactement cela que traite l'article "From "Vibe Checks" to Continuous Evaluation: Engineering Reliable AI Agents" : celui-ci aborde un problème majeur dans le développement d'IA, le piège du "vibe check" (l'évaluation au ressenti). Un prompt qui fonctionne parfaitement lors d'un test manuel peut s'effondrer en production à cause de la nature probabiliste des LLMs (hallucinations, oublis de sources, etc.). Pour passer de simples démos à des systèmes robustes en production, les ingénieurs doivent adopter l'Évaluation Continue (Continuous Evaluation - CE).
Voici les points clés à retenir :
1. Deux modes de pensée : Découverte vs Défense
Pour structurer le travail, l'ingénierie IA doit être divisée en deux phases distinctes :
Mode Découverte : c'est la phase créative. On teste des prompts, on explore les capacités du modèle et on utilise les fameux "vibe checks" (à la main) pour ajuster le tir sur un petit échantillon.
Mode Défense : c'est la phase d'industrialisation. On met en place des tests de régression automatisés sur des milliers de requêtes, sans intervention humaine, pour garantir la stabilité et respecter les SLOs (objectifs de niveau de service).
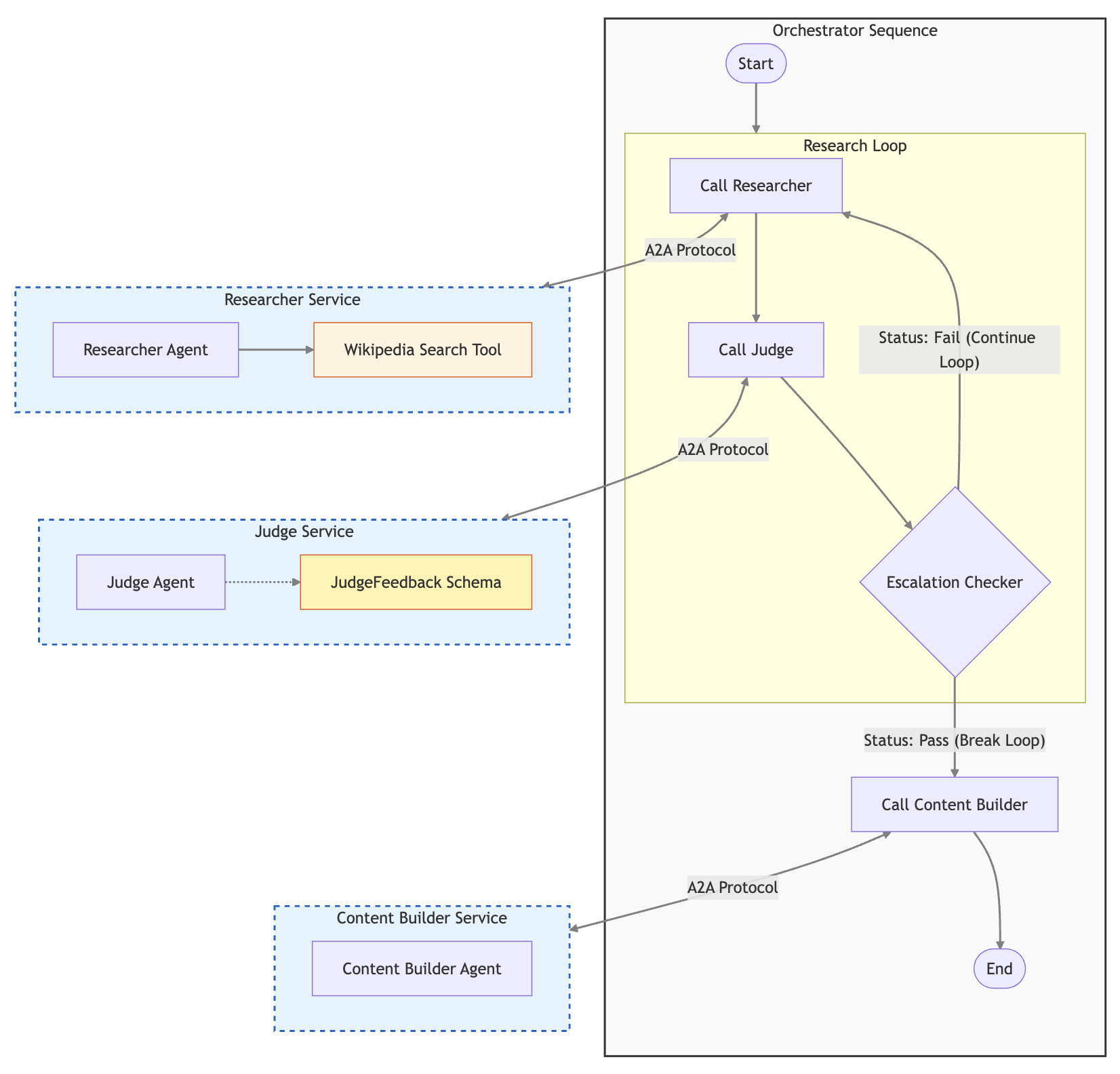
2. Une architecture Multi-Agents modulaire
L'article prend l'exemple d'un système de création de cours divisé en plusieurs agents spécialisés (Chercheur, Juge, Rédacteur, Orchestrateur) communiquant via le protocole standardisé Agent2Agent (A2A) sur Cloud Run.
Avantage : Séparer les préoccupations permet de tester et d'évaluer chaque agent individuellement sans avoir à évaluer tout le système d'un coup. Le "Juge" est d'ailleurs séparé pour éviter qu'un agent n'évalue ses propres hallucinations.
3. La taxonomie de l'évaluation
Pour mesurer la qualité de l'IA, il faut des métriques précises, divisées en trois niveaux :
Niveau 1 : Métriques "techniques" : Vérifications déterministes (le JSON est-il valide ? Le format correspond-il à une Regex ?).
Niveau 2 : Métriques basées sur des grilles d'évaluation, "Rubrics" en anglais (LLM-as-a-judge) : Utilisation d'un modèle pour noter sémantiquement la réponse selon des critères fixes ou générés dynamiquement (cohérence, respect des instructions), exactement comme dans l'enseignement supérieur pour évaluer les étudiants.
Niveau 3 : Métriques gérées (Vertex AI) : Modèles pré-entraînés par Google pour évaluer spécifiquement l'ancrage factuel (Grounding), la sécurité ou la qualité d'utilisation des outils.
4. Le moteur et les données d'évaluation
Une bonne évaluation nécessite un jeu de données de référence robuste contenant :
Le prompt d'entrée.
La réponse de référence (optionnelle).
La trajectoire d'outils attendue (ex: l'agent devait absolument chercher sur Wikipédia avant de répondre). Le moteur d'évaluation exécute ces tests en parallèle et capture la trace de raisonnement (tous les événements intermédiaires et appels d'outils) pour comprendre pourquoi une IA s'est trompée.
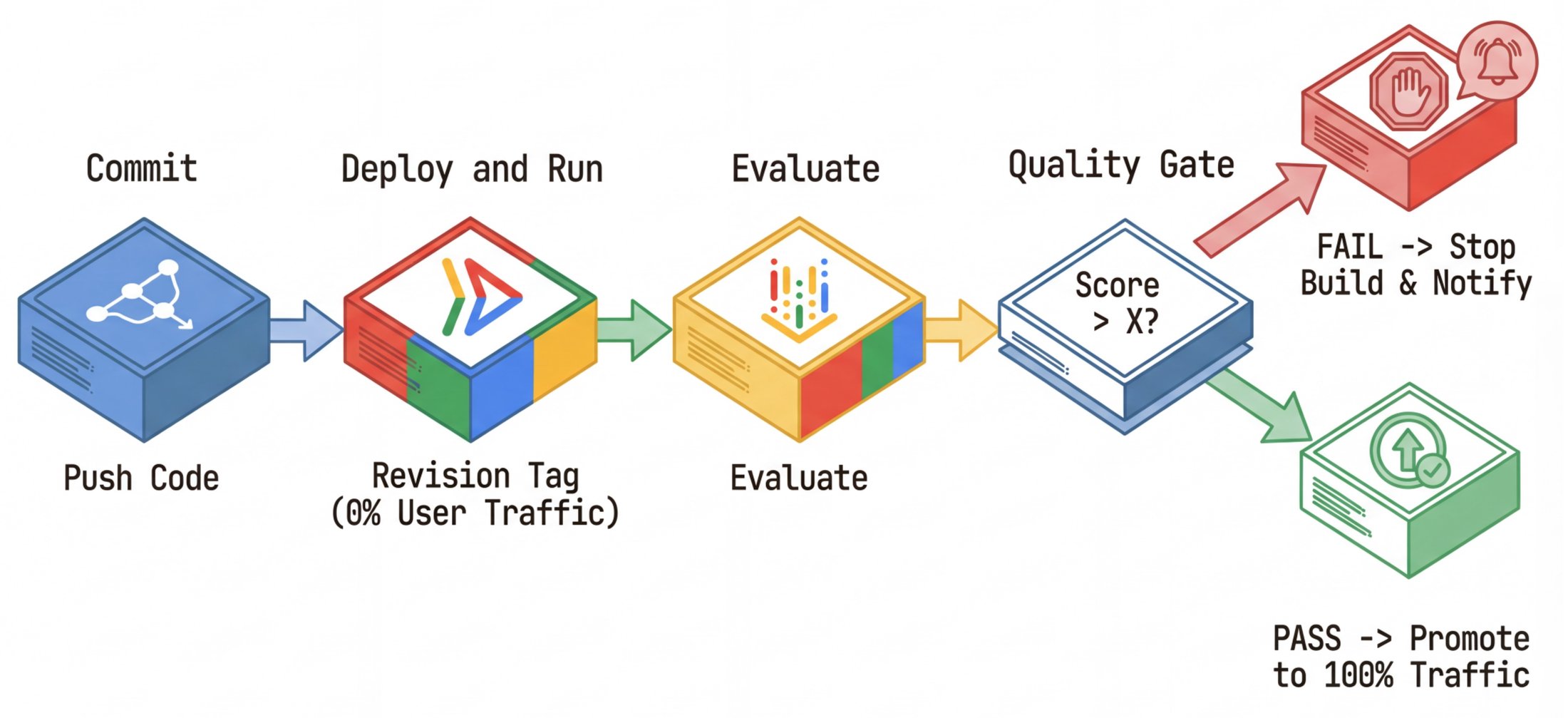
5. Déploiements "Shadow" et automatisation CI/CD
Pour tester un nouveau prompt sans risquer de casser la production, l'auteur recommande les déploiements fantômes (Shadow Deployments).
Une nouvelle version de l'agent est déployée sur une URL cachée qui ne reçoit aucun trafic utilisateur réel.
Le pipeline CI/CD (via Cloud Build) envoie le jeu de données d'évaluation sur cette URL fantôme.
La règle stricte : Si le score d'évaluation est sous le seuil requis, le déploiement est bloqué. Si tout est vert, le trafic est basculé vers la nouvelle version.
6. Observabilité : Traces système vs Traces de raisonnement
Pour déboguer un système multi-agents complexe, les simples logs textuels ne suffisent pas. Il faut combiner :
Les traces de raisonnement : Ce que l'IA a "pensé" (ex: "Je dois chercher X").
Les traces système (via OpenTelemetry et Cloud Trace) : Le parcours technique de la requête (ex: l'outil Wikipédia a mis 5 secondes à répondre, provoquant un timeout). C'est cette combinaison qui permet de savoir si une erreur vient d'une hallucination du modèle ou d'une défaillance réseau.
En conclusion : Il ne faut plus modifier ses prompts à l'aveugle au moindre bug. Traitez vos agents IA comme du vrai code logiciel en automatisant leur évaluation avec des données fiables et des pipelines stricts.
Le modèle Gemini 3.1 Flash Image (nom de code Nano Banana 2) débarque en public preview, offrant une génération d'images de haute qualité avec une latence réduite et des coûts optimisés.
Les points clés à retenir :
Des fonctionnalités professionnelles et haute résolution : il débloque des outils premium tels que le rendu de texte précis directement dans l'image, la traduction, ainsi que la mise à l'échelle (upscaling) en 2K et 4K.
Cohérence des personnages et des objets : l'outil permet de conserver l'apparence de vos sujets sur plusieurs images (jusqu'à 5 personnages et 14 objets), facilitant ainsi la création de storyboards ou de campagnes narratives cohérentes.
Flexibilité des formats et qualité des détails : il prend en charge nativement plusieurs formats d'image (16:9, 9:16, 2:1, etc.) tout en offrant des textures plus riches et un éclairage plus dynamique.
Transparence et sécurité : grâce aux technologies SynthID et C2PA, il offre une transparence totale permettant de savoir non seulement si l'IA a été utilisée, mais aussi comment elle l'a été.
Côté Gemini Enterprise, on note l'arrivée très pratique de nouveaux connecteurs de données pour HubSpot, Monday et Shopify. De plus, le partage d'agents (qu'ils soient créés via Agent Designer, custom ou Google-made) est désormais en disponibilité générale (GA), avec des contrôles d'administration affinés permettant le partage direct entre utilisateurs.
Enfin, l'intégration de Gemini dans vos IDE s'améliore avec le passage en GA des fonctionnalités file outline et finish changes dans IntelliJ.
BigQuery
L'IA s'immisce encore un peu plus dans nos entrepôts de données avec la possibilité de créer et réviser des termes de glossaire personnalisés pour l'agent d'analyse conversationnelle (en Preview). Par ailleurs, "ouf" de soulagement pour les requêtes un peu trop hâtives : vous pouvez désormais restaurer un dataset supprimé (GA) s'il se trouve encore dans votre fenêtre de time travel 😰.
Cloud SQL & AlloyDB
Le troubleshooting devient (presque) un plaisir. Les capacités d'investigation de Gemini Cloud Assist sont maintenant en Preview pour vous aider à analyser les requêtes lentes sur PostgreSQL, MySQL, SQL Server et AlloyDB.
Côté infrastructure, la création d'instances Cloud SQL avec PITR (Point-in-Time Recovery) activé est nettement accélérée grâce à l'utilisation initiale d'instant snapshots plutôt que de backups standards.
Spanner
Plein de nouveautés sous le capot pour notre base relationnelle distribuée : des "versions" de chaînes JSON sont désormais disponibles pour extraire plus facilement les statistiques de transactions et requêtes (dialecte PostgreSQL). Pour l'optimisation, un nouveau motif de diagnostic fait son apparition en GA pour détecter les hotspots insolubles. L'autoscaler managé gère maintenant l'utilisation cible du CPU global et le partitionnement d'instances. Enfin, Spanner enrichit ses outils de gestion avec la possibilité de surveiller l'utilisation des éditions Enterprise/Plus, de rétrograder l'édition depuis la console, et de définir des contraintes d'édition dans vos politiques d'organisation.
Produits Data en vrac... 📦
Vertex AI : Le service Vertex AI Agent Engine passe officiellement en GA. Du côté de Vertex AI Search, vous pouvez désormais basculer d'une tarification configurable vers un modèle de facturation général (pay-as-you-go) 🎉.
Sensitive Data Protection : Le service est maintenant capable de découvrir et profiler les données sensibles sur les jobs de tuning Vertex AI. De plus, plusieurs règles d'ajustement et d'exclusion basées sur l'image passent en GA.
Dataplex : Les aspects de profil de données sauvegardés dans Universal Catalog peuvent maintenant atteindre 1 Mo.
Dataflow : Le support des VM basées sur processeurs Arm (série C4A) est en GA, idéal pour optimiser le ratio prix/performance de vos pipelines.
Oracle Database@Google Cloud : Le service Autonomous Database pose ses valises dans la région Osaka, au Japon.
Cortex : Déploiement de la release mineure 6.3.4.
Autres produits ☁️
Sécurité & SecOps : Google SecOps ajoute le support en Preview pour VPC Service Controls afin de limiter les risques d'exfiltration. On note aussi l'introduction très attendue des cross joins dans les requêtes YARA-L multi-étapes, et l'arrivée de contrôles RBAC pour restreindre la visibilité des métriques d'ingestion. De son côté, Security Command Center permet désormais de filtrer les résultats pour ne voir que les ressources enregistrées via l'intégration App Hub.
Google Kubernetes Engine : Support en Public Preview des instances bare metal c4a-highmem-96-metal pour les clusters Standard.
Compute Engine & Migration : Les VM de série H4D, propulsées par des processeurs AMD EPYC Turin et optimisées pour le calcul haute performance (HPC), sont désormais en GA. Côté migration, Migration Center introduit en Preview la visualisation des dépendances réseau.
NetApp Volumes : Pleins de nouveautés avec le support en Preview des Flex Unified large volumes (jusqu'à 20 PiB !) et le passage en GA du stockage bloc avec protocole iSCSI. Sont également introduits le mode ONTAP pour un accès direct à l'API sous-jacente, et le chiffrement des sauvegardes par clés gérées par le client (CMEK).
Cloud Run & Cloud Run functions : Possibilité de déployer un service multi-régions hautement disponible via le service health external traffic (Preview). Pour l'IA, un serveur MCP distant permet aux agents de se déployer avec Cloud Run (Preview). Enfin, le Direct VPC egress pour les fonctions de 2ème génération passe en GA.
Réseau : Le mTLS backend pour les Load Balancers internes cross-région est GA. De plus, les buckets backend Cloud Storage sont désormais supportés pour les Application Load Balancers dans un environnement Shared VPC. Cloud NGFW introduit les contextes réseau pour simplifier vos règles de pare-feu. Network Intelligence Center améliore grandement ses tests de connectivité avec la détection automatique du VPC de destination et l'évaluation du routage des sous-réseaux hybrides.
Cartographie : Les SDK iOS pour Places et Navigation passent en version 10.10.0. Le Places SDK s'enrichit de la fonctionnalité Search Along Route et de dizaines de nouveaux champs de données. Le Navigation SDK met à jour le comportement de son chevron pour les cyclistes et ajoute un contexte de localisation enrichi pour de meilleurs guidages.
Observabilité & Inventaire : Cloud Trace permet de définir des paramètres par défaut pour les buckets d'observabilité (Preview). Cloud Asset Inventory rend de nouveaux types de ressources (Load Balancing, Network Services API) interrogeables publiquement.
Apigee & CCaaS : Apigee API hub lance en Preview le specification boost, un add-on IA qui améliore automatiquement la lisibilité de vos spécifications d'API. De son côté, Google Cloud CCaaS déploie un patch 4.0 corrigeant notamment le routage des messages vocaux.
A savoir... 🧐
Quelques changements et correctifs importants à garder en tête cette semaine :
Dépréciations et changements : Préparez vos migrations ⚠️ : BigQuery limitera l'utilisation du Legacy SQL à partir de juin 2026 pour les projets inactifs sur ce dialecte. Côté IA générative, le modèle de partenaire Anthropic Claude 3 Haiku est déprécié sur Vertex AI (fin de vie en août 2026). L'API Drive déprécie quant à elle le paramètre enforceExpansiveAccess.
Mises à jour techniques :
GKE déploie massivement de nouvelles versions de patchs (de la 1.30 à la 1.35) sur l'ensemble de ses canaux et bascule automatiquement les remises sur engagement d'utilisation (CUDs) flexibles vers un modèle basé sur les dépenses.
Cortex ajoute le support d'Airflow v3 pour les DAGs Composer.
Bonne nouvelle pour les data scientists : Cloud Translation LLM supporte désormais le finetuning complet avec LoRA.
Enfin, le SecOps Marketplace met à jour ses intégrations pour Google Workspace (nouvelle action Remove Extension) et Microsoft 365 Defender (support de l'API Graph).
Correctifs et Sécurité : Des correctifs de sécurité critiques (CVE) et des résolutions de bugs (fuite de mémoire, erreurs TLS) ont été appliqués sur Apigee X. Du côté de Google SecOps, l'agent distant retire le support vieillissant de Python 3.7. Enfin, Dataproc a corrigé un problème de configuration gsutil sur les images personnalisées.
C'est tout pour cette semaine : bon code, bonnes expérimentations et à la semaine prochaine pour de nouvelles aventures dans le cloud ! 🚀 ☁️
AI values Data. Data values Business.
Unlocking Business Value through Data, Cloud, and Machine Learning Solutions
👋 Hello ! Je suis Vincent, Architecte IA et Lead Data Scientist. Avec ma société TerraQuant, j’aide les entreprises à exploiter leurs données et à intégrer des solutions d’intelligence artificielle pour générer de la valeur. Je me suis spécialisé dans la conception de solutions IA, et je conçois des architectures data performantes et évolutives. Besoin de conseils pour vos projets data ou IA ? 🚀 Je suis là pour vous aider à transformer vos idées en solutions concrètes ! Restez au courant de mes dernières actualités via mes newsletters.