AI values Data. Data values Business.
👋 Hello ! Je suis Vincent, Architecte IA et Lead Data Scientist. J’aide les entreprises à exploiter leurs données et à intégrer des solutions d’intelligence artificielle pour générer de la valeur. Je me suis spécialisé dans la conception de solutions IA, et je conçois des architectures data performantes et évolutives. Besoin de conseils pour vos projets data ou IA ? 🚀 Je suis là pour vous aider à transformer vos idées en solutions concrètes ! Restez au courant de mes dernières actualités via mes newsletters.
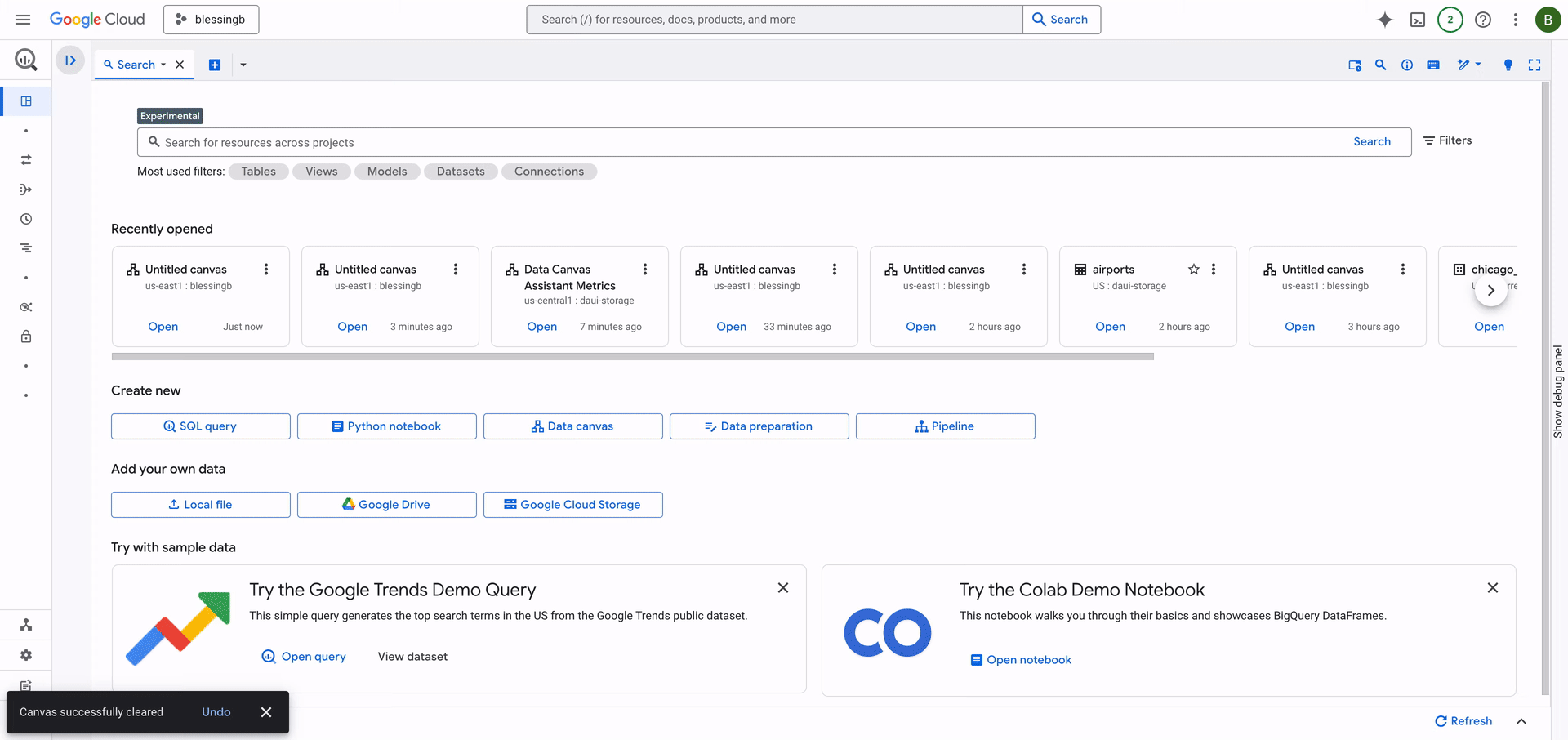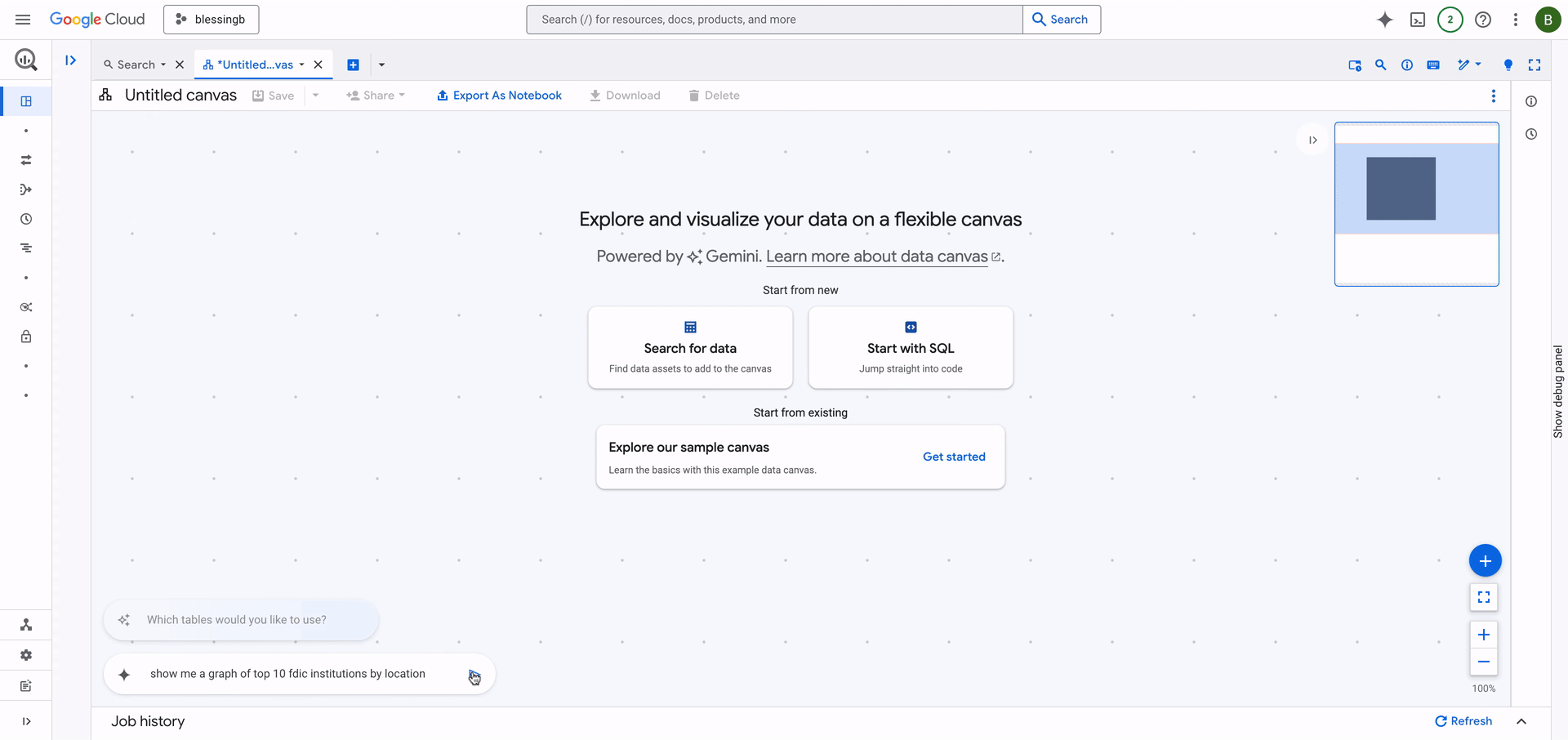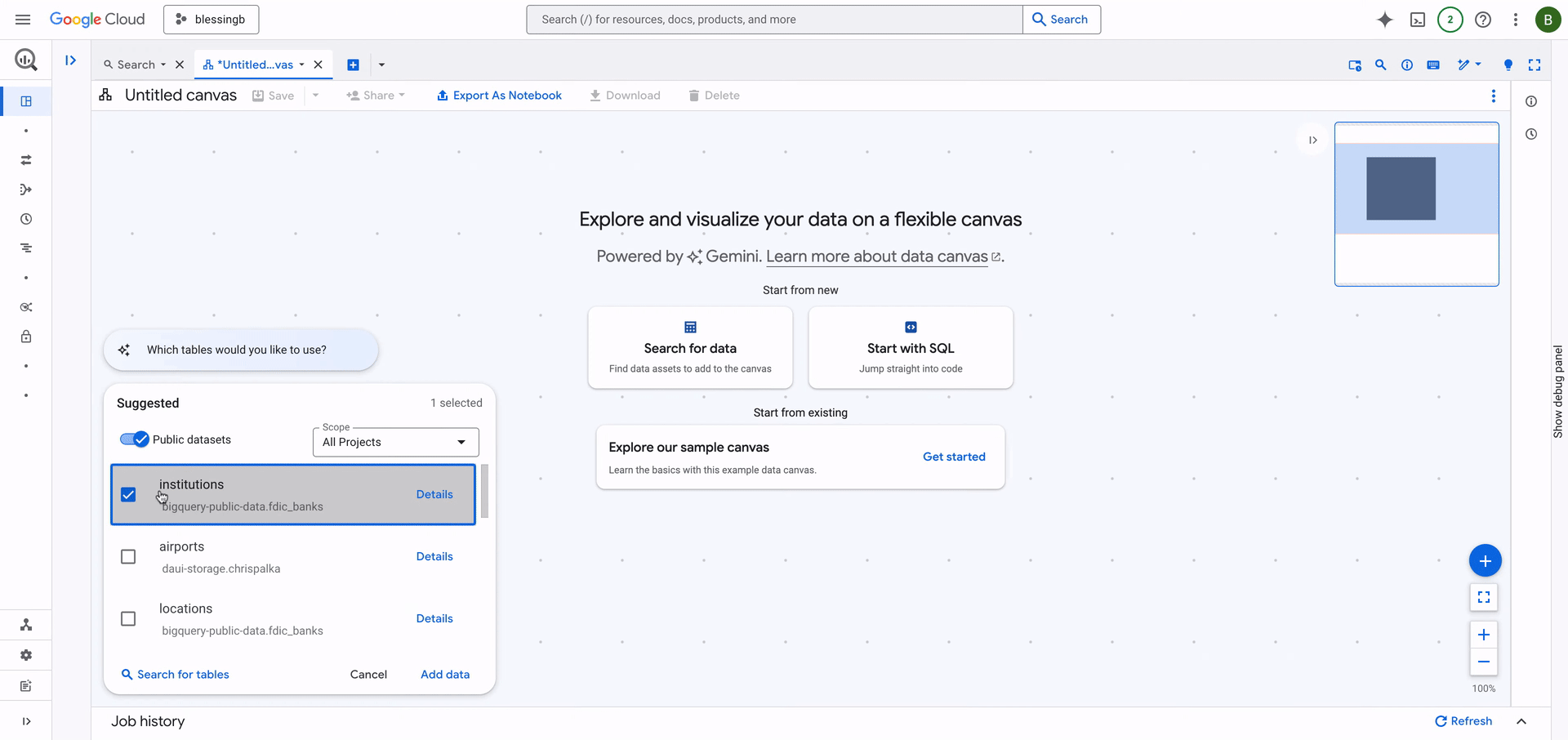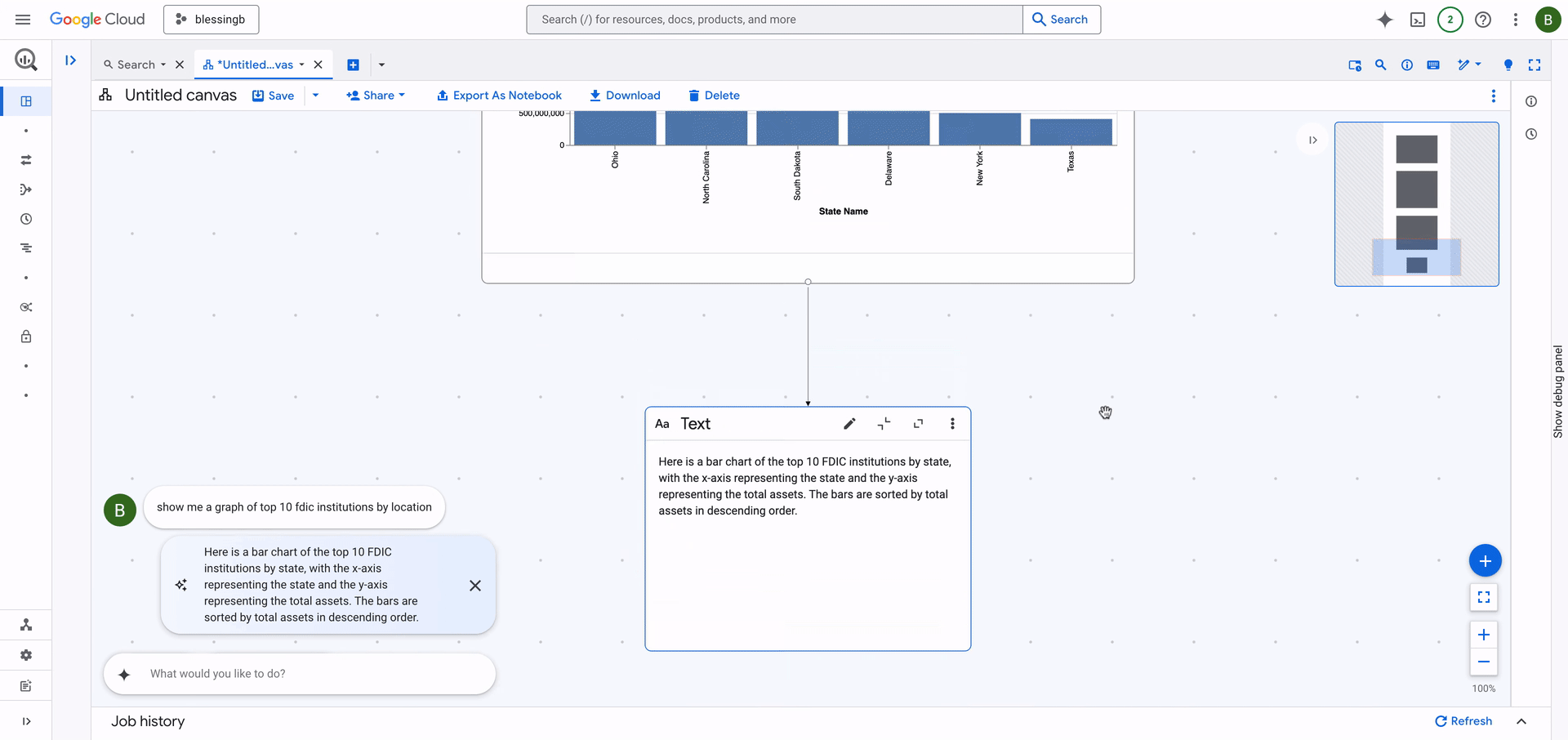
Semaine du 19 avril 2025 au 25 avril 2025Hello ! 👋 Une semaine bien remplie sur GCP, surtout côté Data et IA. BigQuery continue de s'enrichir avec Gemini et plus de flexibilité sur les réservations, Looker intègre Gemini par défaut (attention aux admins !), et Spanner nous offre plus de souplesse avec ses tables. On a aussi des nouveautés pour Colab Enterprise, Contact Center AI Insights, et plein d'autres choses. Côté autres services, Compute Engine sort de nouvelles machines C4D en preview et Cloud Run supporte Python 3.13. Et une nouveauté dans cette NL 👇 Le coin de l'architecte 📐Une nouvelle section fait son apparition ! Elle sera là de temps à autre pour vous donner un feedback lié à l'actualité GCP, au sens large (dans ce cas par exemple, je rebondis sur une vidéo du channel YT Google Cloud). Je voulais vous partager une vidéo récente Google Cloud qui explique les différentes stratégies pour déployer un LLM via Cloud Run (ça mentionne DeepSeek, mais ça peut être n'importe quel modèle) : La vidéo renvoie vers plusieurs docs, dont celle-ci : Best practices: AI inference on Cloud Run with GPUs. Pour l'avoir expérimenté moi-même sur le backend de mon app Metropolia qui permet de requêter l'open data des villes en langage naturel (pub !) et qui tourne sur Cloud Run, j'ai testé toutes les stratégies proposées de la doc sans le savoir 😅 (je ne savais même pas que cette doc existait). Le feedback que je peux donner : déjà, sans surprise, le mieux est d'héberger le modèle sur Cloud Storage : oubliez les solutions de téléchargement à la volée (trop instable) ou d'insertion du modèle dans l'image (trop lourd). Deux solutions s'offrent alors à vous : avoir un point de montage GCS FUSE, et monter le modèle en mémoire comme si vous lisiez à partir d'un filesystem, ou copier localement le modèle (il faut prévoir une taille de volume suffisante). Contrairement à ce que dit la doc concernant le point de montage FUSE (je cite "Not difficult to set up, [...]"), il est en vérité beaucoup plus simple d'effectuer la copie du modèle moyennant un volume Cloud Run suffisant. Côté perfs, aucune différence entre FUSE et copie GCS si le modèle principal est stocké dans un seul gros fichier, plus avantageux pour la copie GCS si plusieurs fichiers volumineux existent grâce à la copie parallèle. Pourtant, on pourrait croire qu'à temps de transfert réseau égal, se passer de l'étape écriture (filesystem local Cloud Run) pour n'avoir que la lecture afin de mettre le modèle en mémoire permettrait de gagner du temps : dans mon cas, ça n'a pas donné le gain escompté malheureusement, le temps de chargement étant peu significatif par rapport au temps de la copie. Concernant le "cold start" de Cloud Run, même avec la copie GCS parallèle, il ne faudra pas s'attendre non plus à des uptimes de folie, sachant que votre image de base embarquera PyTorch ou Tensorflow (ou les 2) qui fera grossir celle-ci et son temps de mise à dispo sous forme de container. Le nombre minimal d'instances à 1 permet de résoudre cela mais ça a un coût (et dans ce cas, Compute Engine peut être envisagé). Quoique vous choisissiez, il faudra anticiper les "cold start" des autres instances en cas de scaling. Donc cela se fait, mais pas de recette magique ! 🙂↔️🪄 Allez, on passe aux news GCP 😉. Data et IA 🧠BigQueryBelle semaine pour BigQuery ! ✨ Vous pouvez maintenant papoter avec un assistant basé sur Gemini directement dans le data canvas de BigQuery pour vous aider dans vos analyses (en Preview).
Côté gestion des ressources, plus de flexibilité : il est possible de spécifier quelle réservation utiliser pour une requête au moment de l'exécution et de définir des stratégies IAM directement sur les réservations (en Public Preview). Toujours sur les réservations, on peut désormais fixer une limite maximale de slots et allouer équitablement les slots inactifs entre les réservations d'un même projet admin (en Public Preview également). Pour les fans d'Iceberg, le contrôle d'accès fin sur les tables Iceberg du metastore BigQuery est maintenant en disponibilité générale (GA). Enfin, une annonce importante ℹ️: BigQuery propose maintenant des remises proportionnelles à l'usage (CUDs) pour les ressources de calcul PAYG (Pay-As-You-Go) listées ici, avec des engagements de 1 ou 3 ans. 💰 Vous vous engagez à dépenser un montant minimum par heure sur une période d'un an (10% de remise) ou trois ans (20% de remise). Chaque heure, votre utilisation réelle est comparée à votre engagement :
Après l'augmentation de 25% en 2023 du PAYG, cela peut permettre de revenir "un peu" en arrière sur les dépenses de ce type 😅. LookerAttention, changement en vue ⚠️ ! Après le 23 mai 2025, Gemini dans Looker sera activé par défaut pour les instances Looker (original) hors région EMEA. Les admins Looker peuvent désactiver cette activation automatique via le paramètre "Automated Gemini in Looker enablement and user management". Par ailleurs, Looker (Google Cloud core) supporte maintenant le mirroring des groupes Google lors de l'utilisation de l'authentification OAuth. SpannerFlexibilité accrue pour vos schémas : Spanner permet désormais d'utiliser la clause Colab EnterprisePour bien démarrer vos projets, la galerie de notebooks est maintenant disponible ! 🎉 Elle propose une collection de templates et d'exemples prêts à l'emploi pour apprendre de nouvelles techniques et découvrir les bonnes pratiques. Contact Center AI InsightsLe contrôle d'accès devient plus précis ! Quality AI propose désormais un contrôle d'accès fin (en Preview). Vous pouvez utiliser des rôles IAM personnalisés et des vues autorisées pour définir qui peut voir quelles parties de votre jeu de données. 🕵️♀️ Datastore / FirestoreBonne nouvelle pour optimiser les coûts : les remises proportionnelles à l'usage (CUDs) sont maintenant en disponibilité générale (GA) pour Firestore et Firestore en mode Datastore. Engagez-vous sur 1 ou 3 ans pour une certaine dépense en opérations lecture/écriture/suppression et bénéficiez de tarifs réduits. Plus d'infos sur les CUDs Firestore et les CUDs Datastore. Dataproc MetastoreLa sécurité s'améliore pour les services multi-régionaux : ils supportent maintenant l'utilisation de clés de chiffrement gérées par le client (CMEK), actuellement en Preview. 🔑 AI Applications (Vertex AI Search)Pour affiner l'évaluation de la pertinence des réponses générées, l'API de vérification du grounding (check grounding) fournit maintenant des scores au niveau de chaque affirmation (claim-level scores) dans une réponse candidate, en plus du score global. Cette fonctionnalité est en disponibilité générale (GA). ✅ AlloyDBPour vous aider à optimiser vos instances, 8 recommenders AlloyDB sont maintenant en disponibilité générale (GA) ! Ils couvrent des aspects comme l'activation des plans de sauvegarde, l'audit de base de données, la haute disponibilité, la politique de mots de passe, le chiffrement SSL/TLS, l'augmentation de la rétention des sauvegardes, l'augmentation du quota de stockage et l'optimisation des instances sous-provisionnées. Produits Data en vrac... 📦
Autres produits ☁️
A savoir... 🧐Quelques points importants à noter cette semaine : côté dépréciations, l'application Looker Mobile (Legacy) sera arrêtée le 1er mars 2026 (utilisez la nouvelle app Looker), Saxml sur GKE n'aura plus de mises à jour (migrez vers JetStream), et Cloud Load Balancing (Global external ALB et Classic ALB) n'autorisera plus les en-têtes personnalisés faisant référence à des en-têtes hop-by-hop spécifiques à la connexion pour HTTP/1.1 à partir du 28 avril 2025. Des correctifs ont été déployés pour Google Distributed Cloud (fuites d'interfaces réseau, jobs kube-proxy, création de cluster, reset bmctl, upgrades Dataplane V2), Backup and DR (jobs bloqués, messages d'erreur, logging, synchro console, threads, import de logs, timeouts PostgreSQL, mounts LVM, noms de BDD), et un bug de logging Apps Script pour les modifications Sheets par triggers temporels. Des mises à jour de sécurité concernent Backup and DR (CVE kernel) et Google Distributed Cloud (VMware & bare metal). Des changements non bloquants incluent une nouvelle version de Policy Controller (1.20.2), la mise à jour d'etcd pour GDC, l'ajout du scope OAuth Google Drive pour Earth Engine (Python & JavaScript), le changement de version par défaut pour Cloud Composer (vers Composer 3 / Airflow 2 à partir de juin 2025), et une simplification des rôles IAM requis pour la préparation de données BigQuery (les rôles BigQuery Studio User et Gemini for Google Cloud User suffisent maintenant, voir ici). Enfin, des mises à jour de bibliothèques clientes sont disponibles pour Datastore (Python), Dataflow (Go), Cloud Logging (Python), Bigtable (Python), et BigQuery (Node.js). Consultez les Cloud SDK pour les détails. Voilà pour les news ! A la semaine prochaine pour d'autres releases GCP. 👍 |
AI values Data. Data values Business.
👋 Hello ! Je suis Vincent, Architecte IA et Lead Data Scientist. J’aide les entreprises à exploiter leurs données et à intégrer des solutions d’intelligence artificielle pour générer de la valeur. Je me suis spécialisé dans la conception de solutions IA, et je conçois des architectures data performantes et évolutives. Besoin de conseils pour vos projets data ou IA ? 🚀 Je suis là pour vous aider à transformer vos idées en solutions concrètes ! Restez au courant de mes dernières actualités via mes newsletters.